






I. Objectifs▲
Maintenant qu'il est possible de créer une scène simple, il est nécessaire de l'accélérer. Pour cela, il va falloir :
- utiliser une structure accélératrice pour les objets statiques,
- regrouper le raytracer dans une seule unité de compilation, afin d'optimiser les appels aux fonctions
II. Utilisation d'une structure accélatrice pour les primitives▲
Une structure accélératrice va permettre d'optimiser les tests sur les primitives. Au lieu de toutes les tester, seules certaines le seront. Pour cela, on va utiliser un kd-tree. Cette structure est un arbre binaire de recherche où chaque noeud pourra être découpé selon l'un des 3 axes en n'importe quel endroit, mais on ne va pas chercher à l'équilibrer. De cette manière, la majorité des feuilles de l'arbre seront vides et peu de tests de primitives devront être effectués. La raison du choix d'un tel arbre découle des différents arguments proposés par Havran dans sa thèse de doctorat (voir les lien en fin d'article).
Pour plus de détails, je vous invite à lire les premiers chapitres de cette thèse. Je ne reprendrai que les éléments permettant de comprendre la création et le parcours de l'arbre.
II-A. Création de l'arbre binaire▲
Lors de la création de l'arbre, plusieurs points doivent être pris en compte :
- Un noeud doit-il être découpé, et si oui comment ?
- Comment déterminer les paramètres de découpage des noeuds ?
Donc après avoir vu le premier point, je m'attaquerai au code proprement dit, puis à une méthode automatique de paramétrisation de la construction.
II-A-1. Le calcul du coût▲
L'idée est de dire que la probabilité qu'un rayon touche la boîte englobante (la bounding box) est proportionnelle à la surface (SAH pour Surface Area Heuristic). On peut alors considérer que le coût d'un noeud est égal à cette surface multipliée par le nombre de primitives associées au noeud.
Afin de découper un noeud, il faut donc calculer un autre coût, celui de parcourir deux noeuds, au lieu d'un seul. C'est alors le coût de l'algorithme de traversée auquel on ajoute le coût de chacun des sous-noeuds. Pour déterminer les sous-noeuds, il faut savoir où le noeud doit être découpé. D'un point de vue optimisation, ces solutions minimales sont les bordures des primitives dans le noeud. On va donc parcourir toutes ces possibilités sur tous les axes pour déterminer le meilleur choix.
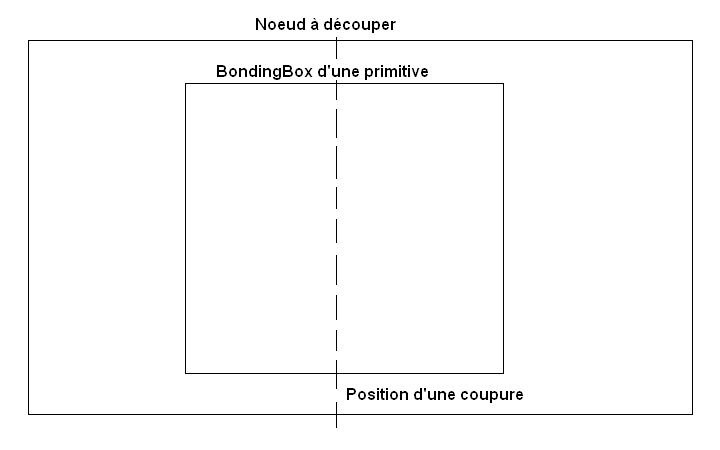
Lors du découpage, il est évident qu'une primitive peut être présente dans plusieurs noeuds. En effet, si le découpage d'un noeud est effectué dans la bounding box de la primitive, il faudra la tester dans les deux sous-noeuds, comme cela se voit sur la figure suivante.
II-A-2. Construction récursive▲
Je passe sur la définition de l'arbre binaire. Le code est visible dans le fichier kdtree.h, et il est plutôt simple dans sa version non optimisée. La seule optimisation est le fait que les noeuds sont contigus en mémoire (il s'agit d'un vecteur alloué au départ).
La première étape consiste à récupérer les positions acceptables pour découper un noeud. Tous les bords des bounding boxes des primitives qui sont strictement dans la bounding box courante sont des candidats potentiels.
static std::set<std::pair<int, DataType> > getSplitPositions(const KDTree<Primitive>::KDTreeNode* node, const BoundingBox& bb)
{
std::set<std::pair<int, DataType> > split_positions;
for(std::vector<Primitive*>::const_iterator primitive = node->getPrimitives()->begin(); primitive != node->getPrimitives()->end(); ++primitive)
{
const BoundingBox& bb_primitive = (*primitive)->getBoundingBox();
for(int i = 0; i < 3; ++i)
{
if (bb_primitive.corner1(i) > bb.corner1(i) && bb_primitive.corner1(i) < bb.corner2(i))
{
split_positions.insert(std::make_pair(i, bb_primitive.corner1(i)));
}
if (bb_primitive.corner2(i) > bb.corner1(i) && bb_primitive.corner2(i) < bb.corner2(i))
{
split_positions.insert(std::make_pair(i, bb_primitive.corner2(i)));
}
}
}
return split_positions;
}Lors du calcul du coût associé avec une position, on va aussi précalculer les vecteurs de primitives associés à chaque noeud, ceci pour éviter de recalculer cela par la suite.
static DataType computeCost(int axis, DataType split_position, const BoundingBox& bb,
const std::vector<Primitive*>* primitives, std::vector<Primitive*>& right_primitives,
std::vector<Primitive*>& left_primitives)
{
BoundingBox bb_right, bb_left;
bb_right = bb_left = bb;
bb_right.corner1(axis) = split_position;
bb_left.corner2(axis) = split_position;
for(std::vector<Primitive*>::const_iterator primitive = primitives->begin();
primitive != primitives->end(); ++primitive)
{
const BoundingBox& bb = (*primitive)->getBoundingBox();
if(bb.corner1(axis) < split_position)
{
left_primitives.push_back(*primitive);
}
if(bb.corner2(axis) > split_position)
{
right_primitives.push_back(*primitive);
}
}
return bb_right.SAH() * right_primitives.size() + bb_left.SAH() * left_primitives.size();
}Voici maintenant la véritable fonction récursive qui va construire l'arbre. À partir de l'instance mère de l'arbre (qui permet de récupérer de nouveaux noeuds depuis le vecteur, de contenir les vecteurs de primitives qui seront stockés dans les feuilles de l'arbre), d'un noeud courant et de sa bounding box, on va pouvoir calculer si celui-ci doit être découpé. Trois arguments supplémentaires sont donnés :
- remaining_depth indique la profondeur restante possible pour l'arbre
- remaining_failure est le nombre d'échecs de découpage acceptés (il est possible que par la suite, le coût soit amélioré, donc on peut autoriser les échecs)
- enhancement_ratio_failure est le rapport maximal entre le coût du noeud découpé et celui du noeud non découpé.
Une fois que les positions possibles sont récupérées, le coût minimum est récupéré. Si celui-ci n'existe pas ou si le nombre d'échecs est dépassé, on arrête la récursion. Dans le cas contraire, on valide le découpage, et si la profondeur maximale n'est pas atteinte et s'il reste plus de deux primitives dans les sous-noeuds, on relance le calcul.
static void subdivide(KDTree<Primitive>& tree, KDTree<Primitive>::KDTreeNode* node,
const BoundingBox& bb, int remaining_depth, int remaining_failures, DataType enhancement_ratio_failure)
{
const std::set<std::pair<int, DataType> >& split_positions = getSplitPositions(node, bb);
DataType lowest_cost = std::numeric_limits<DataType>::max();
std::pair<int, DataType> lowest_split = std::make_pair(-1, 0.);
std::vector<Primitive*> right_primitives, left_primitives;
for(std::set<std::pair<int, DataType> >::const_iterator it = split_positions.begin(); it != split_positions.end(); ++it)
{
std::vector<Primitive*> right_primitives_test, left_primitives_test;
DataType new_cost = computeCost(
it->first, it->second, bb, node->getPrimitives(), right_primitives_test, left_primitives_test);
new_cost = (new_cost + 0.3) / (bb.SAH() * node->getPrimitives()->size());
if(new_cost < lowest_cost)
{
right_primitives_test.swap(right_primitives);
left_primitives_test.swap(left_primitives);
lowest_split = *it;
lowest_cost = new_cost;
}
}
if(lowest_split.first != -1 && (lowest_cost < enhancement_ratio_failure || --remaining_failures >= 0))
{
KDTree<Primitive>::KDTreeNode* left_node = tree.getPairEmptyNodes();
KDTree<Primitive>::KDTreeNode* right_node = left_node + 1;
std::vector<Primitive*>* left_store = tree.getNewPrimitivesStore();
left_store->swap(left_primitives);
left_node->setPrimitives(left_store);
std::vector<Primitive*>* right_store = tree.getNewPrimitivesStore();
right_store->swap(right_primitives);
right_node->setPrimitives(right_store);
node->setAxis(lowest_split.first);
node->setSplitPosition(lowest_split.second);
node->setLeftNode(left_node);
node->setLeaf(false);
if(remaining_depth > 0 && left_store->size() > 1)
{
BoundingBox bb_left;
bb_left = bb;
bb_left.corner2(lowest_split.first) = lowest_split.second;
subdivide(tree, left_node, bb_left, remaining_depth - 1, remaining_failures, enhancement_ratio_failure);
}
if(remaining_depth > 0 && right_store->size() > 1)
{
BoundingBox bb_right;
bb_right = bb;
bb_right.corner1(lowest_split.first) = lowest_split.second;
subdivide(tree, right_node, bb_right, remaining_depth - 1, remaining_failures, enhancement_ratio_failure);
}
}
}Le lancement de la construction de l'arbre doit être effectué à la main. Par défaut, le kd-tree n'est pas valide, il est nécessaire de l'initialiser. Pour cela, il faut faire appel à la fonction suivante :
static void custom_build(IRT::SimpleScene* scene, int remaining_depth, int remaining_failures, DataType enhancement_ratio_failure)
{
KDTree<Primitive>& tree = scene->getKDTree();
tree.setPrimitives(scene->getPrimitives());
subdivide(tree, &tree.getNodes()[0], scene->getBoundingBox(), remaining_depth, remaining_failures, enhancement_ratio_failure);
}La question restante est la valeur des différentes paramètres additionnels.
II-A-3. Paramétrage automatique▲
Havran a proposé des équations empiriques de sélection de la profondeur de l'arbre, ainsi que le nombre acceptable d'échecs de découpage pour un noeud.
La profondeur est une fonction affine du logarithme du nombre de primitives, tandis que le nombre d'échecs sera une fonction affine de la profondeur maximale. Ces deux hypothèses sont logiques, l'arbre binaire équilibré ayant une profondeur logarithmique par rapport au nombre de feuilles et plus la profondeur est importante, plus les échecs sont probables.
static void automatic_build(IRT::SimpleScene* scene)
{
// Utilisation des paramètres d'Havran
DataType k1 = 1.2;
DataType k2 = 2.0;
DataType K1 = 1.;
DataType K2 = .2;
int remaining_depth = static_cast<int>(std::ceil(k1 * std::log(static_cast<DataType>(scene->getPrimitives().size())) + k2));
int remaining_failures = static_cast<int>(std::ceil(K1 + remaining_depth * K2));
DataType enhancement_ratio_failure = .75;
custom_build(scene, remaining_depth, remaining_failures, enhancement_ratio_failure);
}Cette fonction est aussi exposée en Python et peut être appelée pour initialiser le kd-tree.
II-B. Utilisation de l'arbre binaire▲
La première étape va être de déporter le test sur les primitives de getFirstCollision() vers une nouvelle fonction qui va prendre un vecteur de primitives en paramètre supplémentaire. Ainsi, il sera possible d'appeler cette fonction depuis une feuille de l'arbre binaire pour ne tester qu'une partie des primitives.
II-B-1. Sélection des noeuds à parcourir▲
Lorsqu'un noeud est parcouru, deux solutions sont possibles. Soit il s'agit d'une feuille de l'arbre, auquel cas on utilisera l'algorithme utilisé jusqu'à présent, soit il faut déterminer si tous les fils doivent être parcourus. Pour cela, à partir du rayon, on détermine les points d'entrée et de sortie de chaque noeud.
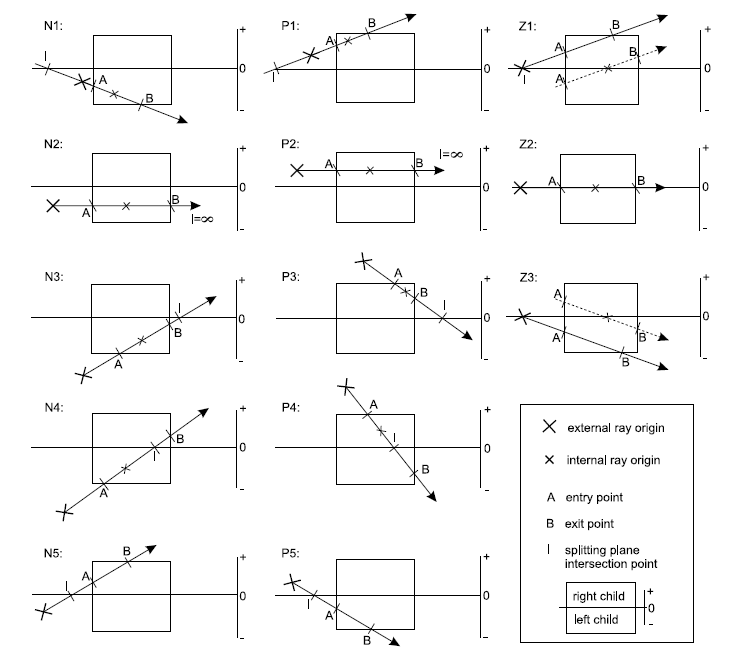
La figure précédente montre les différentes solutions. Le point A est le point d'entrée, B celui de sortie et I est le point milieu entre les deux noeuds. Si I est extérieur aux noeuds, alors seul un noeud doit être parcouru. Dans le cas contraire, on peut connaître le premier noeud à parcourir puis le second.
II-B-2. Parcours de l'arbre▲
Maintenant que la théorie est prête, on peut passer au code.
Pour le moment, le code n'est pas parfait, il existe certaines conditions dans lesquelles le code engendrera des erreurs irrécupérables.
On va commencer par la fonction de parcours récursive. En fait, elle ne va pas être récursive, puisqu'on utilise une pile pour stocker les noeuds restants à parcourir.
La pile est initialisée avec la racine de l'arbre puis avec le point de sortie du parcours. Tant qu'on n'est pas sorti, current_code est un noeud de l'arbre. Et tant que celui-ci n'est pas une feuille de l'arbre, on va empiler les noeuds nécessaires.
Si la feuille parcourue permet de rencontrer une primitive, celle-ci est la plus proche possible (puisqu'on traverse l'arbre depuis les noeuds les plus proches aux plus lointains). Dans le cas contraire, on dépile un noeud et on recommence le parcours.
Primitive* getFirstCollision(const Ray& ray, float& dist, float tnear, float tfar)
{
KDTreeNode* current_node = &nodes[0];
int entrypoint = 0;
int exitpoint = 1;
stack[entrypoint].t = tnear;
if (tnear > 0.0f)
{
stack[entrypoint].pb = ray.origin() + ray.direction() * tnear;
}
else
{
stack[entrypoint].pb = ray.origin();
}
stack[exitpoint].t = tfar;
stack[exitpoint].pb = ray.origin() + ray.direction() * tfar;
stack[exitpoint].node = NULL;
while (current_node != NULL)
{
while(!current_node->isLeaf())
{
current_node = split_node(ray, current_node, entrypoint, exitpoint);
}
Primitive* primitive = current_node->getFirstCollision(ray, dist);
if(primitive != NULL)
{
return primitive;
}
entrypoint = exitpoint;
current_node = stack[exitpoint].node;
exitpoint = stack[entrypoint].previous;
}
return NULL;
}Le découpage est effectué suivant ce qui a été présenté dans la partie précédente. On teste la position des points d'entrée et de sortie pour le rayon, et selon le cas de figure, on travaille sur un fils ou sur deux fils. Dans le cas de deux fils, on empile le noeud avec les éléments nécessaires au parcours.
KDTreeNode* split_node(const Ray& ray, KDTreeNode* current_node, int& entrypoint, int& exitpoint)
{
KDTreeNode* far_node;
int axis = current_node->getAxis();
DataType splitpos = current_node->getSplitPosition();
if (stack[entrypoint].pb(axis) <= splitpos)
{
if (stack[exitpoint].pb(axis) <= splitpos)
{
return current_node->leftNode();
}
if (stack[exitpoint].pb(axis) == splitpos)
{
return current_node->rightNode();
}
far_node = current_node->rightNode();
current_node = current_node->leftNode();
}
else
{
if (stack[exitpoint].pb(axis) > splitpos)
{
return current_node->rightNode();
}
far_node = current_node->leftNode();
current_node = current_node->rightNode();
}
DataType t = (splitpos - ray.origin()(axis)) / ray.direction()(axis);
int tmp = exitpoint++;
if (exitpoint == entrypoint)
{
++exitpoint;
}
stack[exitpoint].previous = tmp;
stack[exitpoint].t = t;
stack[exitpoint].node = far_node;
stack[exitpoint].pb(axis) = splitpos;
int nextaxis = mod[axis + 1];
int prevaxis = mod[axis + 2];
stack[exitpoint].pb(nextaxis) = ray.origin()(nextaxis) + t * ray.direction()(nextaxis);
stack[exitpoint].pb(prevaxis) = ray.origin()(prevaxis) + t * ray.direction()(prevaxis);
return current_node;
}
};III. Résultats▲
Étant donné la scène type, le gain ne va pas être transcendant. Il n'empêche que ce gain existe, aussi faible soit-il. On passe ainsi de 2 secondes à 1.9 secondes sur ma configuration (C2D sous Windows XP). Le coût de test d'intersection avec une sphère est relativement faible, et c'est ce qui peut expliquer cette faible différence.
En ajoutant un parallélépipède droit dans la scène, le coût passe de 4.6 secondes à 4.3 secondes.
Il est possible d'effectuer d'autres tests de rapidité en ajoutant dans le script Python d'autres sphères et en utilisant des profondeurs diverses lors de la création du kd-tree.
IV. Conclusion▲
Pour vraiment tirer parti de cette technique, il va être nécessaire de définir des primitives plus complexes ainsi que des scènes plus ambitieuses. Ce sera l'objectif des prochains tutoriels. Par défaut, le kd-tree n'est pas construit, et le comportement du raytracer reviendra à ce qu'on avait au début de ce tutoriel. Il sera alors aisé de comparer les différences de vitesse.
Lien vers la thèse d'Havran.